Support Vector Classifier for Stock Price Prediction
This report presents an analysis focused on several key areas:
- Utilizing a Support Vector Machine for forecasting upward trends in data.
- Optimizing the estimator through hyperparameter tuning and showcasing the most effective model.
- Assessing the predictive performance using metrics such as the area under the ROC curve, confusion matrix, and a comprehensive classification report.
To structure this analysis, we will adhere to the following seven steps in model building:
| Step 1 | Ideation | Forecasting daily positive returns from financial time series data |
| Step 2 | Data Collection | Retrieve time series data from yahoo finance |
| Step 3 | Exploratory Data Analysis | Conduct analysis of summary statistics and extract relevant input features |
| Step 4 | Cleaning Dataset | No requirement for outlier removal or data imputation in this simplified scenario |
| Step 5 | Transformation | Apply feature scaling methods like normalization and standardization for uniform data comparability |
| Step 6 | Model building and tuning | Develop and refine a Support Vector Machine for classification, focusing on hyperparameter adjustments for optimal model configuration |
| Step 7 | Performance Evaluation | Assess model efficacy using the ROC curve, confusion matrix, and a detailed classification report |
Step 1: Ideation
Our goal is to develop a baseline SVM classifier for predicting the next trading day’s return direction of an asset. This involves tackling a binary classification problem, with potential model outputs being in the set 

$$f : \mathbb{R}^D \to \lbrace 0,1 \rbrace$$
Our data source is the daily log returns from the S&P 500 Index ETF (SPY).
Prior to gathering this time series data, it’s critical to choose a representative sample period for the market in which we aim to make directional forecasts. In the context of financial time series, this means including various market regimes within our sample period. Selecting either too short or excessively long periods could introduce sampling noise and sampling bias, as described by Géron (2019, p.25).
We anticipate the model’s accuracy to be roughly equivalent to random guessing, or optimistically, just over 50%. As our analysis is limited to price-based input features, we do not expect a significant predictive advantage over extended periods.
Step 2: Data Collection
The SPY price data consists of open, high, low and close prices for the sample period from 10/2014 to 09/2022. The selected sample period includes various market events, where stock prices have suffered significant setbacks like
- the Brexit Referendum and US Presidential Elections in 2016,
- the U.S.-China trade war in 2018,
- the COVID-19 pandemic with a market draw down in early 2020,
- the Growth-to-Value style rotation at the end of 2021 with the onset of rising energy prices and inflation,
as well as the intermediate periods, which are characterised by a general upward drift in equity prices.

The following statistics reveal significantly non-normal log returns for the sample. In the following moments test, a p-value 

Step 3: Exploratory Data Analysis (incl. calculation of input features)
We first look at the summary statistics from the log returns of the ETF per year and the entire sample period.

The average daily return is negative in 2015, 2018 and 2022 only. We can also see that both, the most negative and positive daily returns were realized in 2020. These returns could possibly be marked as outliers (beside other returns that lie beyond three standard deviations). In practice, it is necessary to check the impact of these cases, particularly when SVM’s are used, as the support vectors are sensitive to outliers.
We observe a higher rate of positive versus negative daily log returns for the sample period. This is a common problem in machine learning for financial applications and is called the class imbalance problem. The sample period shows 54.6% (1097) positive returns and 45.4% (913) negative returns. This is not quite a big difference, but with the prospect of a model having low expected predictability, the class imbalance may force the model to generate only buy-signals to maximize its accuracy. Attaining a 55% accuracy in predicting the direction of financial returns could be a foundation for exceptional monetary success. The premise for this statement to hold true is that we are able to extend this accuracy to a large number of bets within or across markets. In such a case, a 55% accuracy rate would roughly correspond to an information coefficient of about 10%, according to Grinold and Kahn (2020). Therefore, it is crucial for our model to effectively learn and capture the inherent patterns in asset returns, rather than merely recognizing that recent financial history has shown a higher frequency of positive returns over negative ones.
We will address the issue of class imbalance by applying the class_weight="balanced" parameter in both the LinearSVC and SVC functions. This approach guarantees an equitable weighting across the target labels, calculated using the formula n_samples / (n_classes * np.bincount(y)).
Target label definition
Since we are interested in a tradable signal (i.e. we look for economic inefficiencies rather than purely statistical ones), a dynamic threshold seems to be a better choice than a fixed threshold for the target label definition. We consider a rolling volatility measure as a proxy for variable transaction costs from bid-ask spreads and slippage. The intuition is that transaction costs increase with higher volatility, and hence the threshold for the buy signal is increased. This should lead to more practicable target labels and potentially mitigates the chance of spurious findings.
As a result, small positive returns are labeled as negative returns, which is described by
where 


where 



A side effect from the target label definition is that the class weights become more balanced. After applying the dynamic threshold we can see that the rate of buy-labels shrinks to 49.1% (990).
When we think about heteroscedasticity in financial returns, it would be efficient to apply event based modeling to discretize returns. There are also more enhanced labelling methods that account for practical aspects of financial trading like stop-loss and take-profit orders (De Prado 2018). However, these techniques require intraday return data, which is harder to retrieve from public API’s for longer time horizons. Hence, we keep going with daily close-to-close returns for the time being.
Feature Extraction
We have calculated features as specified in Table 1. As this is an illustrative model, we stick to purely price-based input variables for the sake of simplicity.

We are interested in the properties of the data that allow us to build a sound prediction model that generalizes to out-of-sample data, i.e. it avoids spurious findings. Unfortunately, there is comparably little guidance to be found about this topic in the machine learning literature. Machine learning examples often stay simple for educational purposes and do not address the required data properties. This often suggests that one simply has to throw all the data on a model and hit the button. But this doesn’t lead to actionable results. We have applied tests on stationarity and multi-/collinearity to reduce the feature set where necessary. In practice, the definition of a minimal optimal problem is often preferred, i.e. we want to reduce the input feature set – possibly to a minimum. This should lead us to better results in the classification task. In this sense, we have applied the Augmented Dickey-Fuller test and the Variance Inflation Factor.
Train/Test data split
A test data set is defined, which was hold-out from the model training and used to evaluate the out-of-sample performance of the estimator. This mitigates the problem of overfitting. A share of 20% is a common choice for the size of the test set. However, since we look at one single time series that ends with the COVID-19 market environment, a larger size of 30% seems to be a viable choice. The test set then covers about the full range of the post-COVID-19 market regime.
In general, it has turned out that the determination of a sample period, as well as the size of the test set, has a significant effect on model performance. Model design choices like these should therefore always be made in the context of model utilization and financial markets domain knowledge.
Step 4: Cleaning the Dataset
We won’t need additional data cleaning or imputation. The majority of our input features are binary. The year 2020, notable for having the highest negative and positive daily sample returns, will be excluded from the training dataset and instead used in the test set.
Step 5: Transformation
Data transformation is often crucial to derive valuable information from data, but it’s not guaranteed to always enhance a model’s predictive capability. For models relying on gradient estimation, such as SVM, it’s standard practice to use numeric data that is centered with unit variance. More information can be found in the scikit-learn documentation (https://scikit-learn.org/stable/auto_examples/preprocessing/plot_all_scaling.html#sphx-glr-auto-examples-preprocessing-plot-all-scaling-py).
Feature Selection and Dimensionality Reduction
Since we follow a minimal optimal problem, we use techniques of feature selection and Principal Component Analysis (PCA) to reduce the dimensionality of the input vector. To decide on the optimal number of components, we show the eigenvalues of the original training data in decreasing order in a scree plot. The eigenvalues are de-correlated pieces of variance explained, hence the optimal number of PC’s is indicated by the ‘elbow’ in the scree plot, and is four. These four PC’s account for more than 

The StandardScaler is used for the numerical variables, and the MinMaxScaler is applied to the binary variables. Both of these transformers are part of scikit-learn. We integrate them into a ColumnTransformer, enabling us to apply the respective transformations to all features simultaneously. The StandardScaler normalizes data based on its mean and standard deviation, represented as 

The OneHotEncoder is typically employed for multi-nominal categorical variables, yet in this case, one-hot encoding wouldn’t provide additional insight beyond the 01-coded variable. Standard transformers facilitate easy processing, especially when setting aside a test set, since the test set can be efficiently aligned with the training set’s parameters. This approach is vital to avoid typical data-leakage errors. Additionally, the RobustScaler can be used to mitigate the impact of outliers in numeric features.
Step 6: Modeling and Tuning a SVM Classifier
Two model types have been tested, a linear and a non-linear SVM classifier, which are described in the following.
Linear Model:
Initially, we’ll model using a linear SVM classifier. For this, the LinearSVC estimator is preferred since it’s much faster than its counterpart, SVC(kernel='linear'). Given that the data is not linearly separable, we opt for a soft margin classifier. This approach incorporates slack variables 
where the margin term 

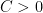



when a vector is not within the margin and on the right side of the hyperplane,
when the vector is within the margin,
when the vector is on the hyperplane, and
when the vector is on the wrong side of the hyperplane.
The loss function of the soft-margin SVM classifier is described as the error between the output of the predictor 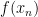

$$l(t) = max \{0, 1-t\}, \;\;\;\; \text{where} \;\; t=yf(x) = y( \langle w, x \rangle + b).$$
We note that the ideal loss function for a binary classification problem would be the zero-one loss, which simply counts the mismatch between the prediction and the true label denoted by 
We can also express the hinge loss for the soft-margin classifier as a piecewise function, given by
The slack variables are chosen such that 
$$\min_{w, b, \xi} \frac{1}{2} ||w||^2 + C \sum_{n=1}^{N} max(0, 1 – y_n( \langle w, x_{n} \rangle + b))$$
The previous description of the SVM in terms of 


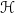

The dual SVM is described by
where the set of inequality constraints is called the box constraints, as the vector of Lagrange multipliers ![\alpha = [ \alpha_1, \dots, \alpha_N ]^T \in \mathbb{R}^N](https://s0.wp.com/latex.php?latex=%5Calpha+%3D+%5B+%5Calpha_1%2C+%5Cdots%2C+%5Calpha_N+%5D%5ET+%5Cin+%5Cmathbb%7BR%7D%5EN&bg=ffffff&fg=000&s=0&c=20201002)
Time Series Cross-Validation:
The cross-validation is applied by using the forward chaining rule, which preserves the temporal order of the time series data. We make 20 splits, which roughly corresponds to a retraining of the model after each five months, and leaves a gap between the training and the test set to avoid a forward looking bias.
Hyperparameter Tuning:
The tuning is applied to the hyperparameters LinearSVM_C__C and LinearSVM_C__penalty using the grid search method.
The hyperparameter
The penalty parameter is used to reduce overfitting by regularization, i.e. the model either applies the 
Non-linear Model:
A SVM assumes a linear classifier. However, we can fit a non-linear model by implicitly creating features that are projected into higher dimensional space. This is called the kernel trick, which is done by embedding the data in an appropriate inner product space in a non-linear mapping 
$$k(x,y) = \langle \Phi(x), \Phi(y) \rangle_{\mathscr{H}}$$
The result from applying the kernel operation 

$$\forall z \in \mathbb{R}^N : z^T K z \geq 0.$$
To solve the loss function for the kernel SVM, we have to apply a subgradient approach, since the hinge loss is not differentiable at its ‘hinge’, where 
The dual SVM yields to a convex quadratic programming problem, given by
where 


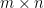

Step 7: Performance Evaluation
The following explains the main performance metrics that are used for model evaluation. The precision is the accuracy of the positive predictions, given by
$$precision = \frac{TP}{TP + FP}$$
The recall is also called sensitivity or true positive rate (TPR), and is used together with the precision measure. The recall is defined as
$$recall = \frac{TP}{TP + FN}$$
The precision and recall are often combined in a harmonic mean, which is called the 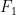
$$F_1 = \frac{2}{\frac{1}{precision} + \frac{1}{recall}} = 2 \times \frac{precision \times recall}{precision + recall} = \frac{TP}{TP + \frac{FN + FP}{2}}$$
The
Linear Model Results:
The results from the linear model are summarized in the following table:

The mutual information is a generalised form of correlation that describes non-linear relationships. The combination of non-linear feature selection with a linear classifier seems to work reasonably well. The linear classifier based on SelectKBest yields to the highest test accuracy. On the other hand, PCA is a linear combination of factor loadings, and the aim of RFECV is to reduce multi-collinearity, so the value added to a linear classifier appears more limited.
The difference between the train and test accuracy indicates that the model overfits to the training set. This could have various reasons:
- the model is inaccurate or inaccurately parametrized for the classification task
- the observed patterns in the training data do not persist in the test data
- the market regime of increasing inflation has changed the market game
Increasing the regularization in the model by reducing the value of
The area under the curve for the receiver operating characteristic (ROC AUC) is commonly used to evaluate binary classification problems. It shows the true positive rate vs. the false positive rate, which means that the larger the ROC AUC is (i.e. the faster it increases to the top left corner), the better the model has learned the actual underlying pattern of the data. The result for the best linear model is shown in Figure 7. The model clearly has no edge in predicting up-moves for the ETF price on a daily basis. The AUC is less than 0.5.


Non-linear Model Results
The results from the linear model are summarized in Table 3:

Again, the combination of linear and non-linear model components seems to work reasonably well. The highest test set accuracy is realized with a non-linear classifier based on the linear PCA factor loadings. This model seems to be more stable in terms of generalization than the linear one. The training and test set have about the same level of accuracy, i.e. the model does not overfit to the training data. As the kernel-based model that uses SelectKBest takes very long to run the cross-validation, only one example with 
The two hyperparameters 
The ROC AUC for the best non-linear model is shown in Figure 9. The model tends to have a higher true positive rate over the false positive rate. This might not lead to an edge in predicting the daily ETF price movements successfully, however, there is some slight improvement over the linear model. The AUC is 0.53.


It is noticeable that the frequency of positive return forecasts increases with the number of PCs in the model, while the classifier’s test accuracy decreases. This underpins that the feature set provides limited information to the model.
References
Gareth James, Daniela Witten, Trevor Hastie, and Robert Tibshirani, 2013. “An Introduction to Statistical Learning with Applications in R.” Springer.
Aurélien Géron, 2019. “Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow.” O’Reilly Media, Inc.
Richard C. Grinold and Ronald N. Kahn, 2020. “Advances in Active Portfolio Management. New Developments in Quantitative Investing.” McGraw-Hill.
Marcos L. De Prado, 2018. “Advances in Financial Machine Learning.” Wiley & Sons.
Marc P Deisenroth, A. Aldo Faisal, and Cheng S. Ong, 2021. “Mathematics For Machine Learning.” Cambridge University Press.
Kevin P. Murphy, 2022. “Probabilistic Machine Learning – An Introduction.” The MIT Press.