Introduction
This detailed report methodically dissects the intricacies of the Black-Litterman model in two comprehensive, interconnected sections. The first section delves into the concept of efficient diversification, grounded in Modern Portfolio Theory (MPT). It critically examines the aspects of mean-variance optimization (MVO), underscoring its significant challenges in real-world application, such as its extreme sensitivity to input parameters and its tendency to produce extreme portfolio weights (corner solutions). We also explore in detail the process of deriving covariance matrices and implementing sophisticated techniques to enhance the reliability of these essential estimations.
The second part of the report systematically unfolds the Black-Litterman model in a five-step framework. Here, the emphasis is on how this model is applied in asset allocation and portfolio selection, demonstrating its effectiveness in overcoming the stability issues linked with MVO, thus facilitating the creation of more resilient portfolios. The Black-Litterman model is particularly noted for its systematic integration of market views, which significantly improves portfolio adaptability and performance.
Our analysis focuses on ten U.S. sector index funds. We exclude the Communication Services sector due to its recent establishment in 2018 within the GICS scheme, having been segmented from previously classified assets in the Information Technology (TECH) and Consumer Discretionary (CDIS) sectors. This reclassification resulted in approximately two-thirds of the market cap of this sector being re-allocated to TECH and the remainder to CDIS:

Additionally, our study encompasses other asset classes to provide a comprehensive view on diversification:

The 3-month treasury bill rate, sourced weekly from the FRED database, is employed as our risk-free rate of return benchmark for the U.S. market.
Our methodology involves the use of weekly data, aiming to optimize the balance between data quantity and quality. This approach contrasts with some analysts who prefer daily returns for calculating covariances, due to the excessive ‘noise’ often found in daily returns. However, daily returns are utilized exclusively for performance metric calculations. Notably, Markowitz’s MVO is designed for discrete returns, calculated as 

The period of analysis spans from July 31, 2006, to October 31, 2019. This timeframe is crucial for our covariance estimation and forms the basis of our portfolio optimization strategy, which is set at the end of this in-sample period. Performance metrics are evaluated for a buy-and-hold approach from December 31, 2019, to October 31, 2022, over three years, without additional portfolio rebalancing.
1. Efficient Diversification
In active portfolio management investment decisions are organized in a top-down, three step process. In the first step, a portfolio manager determines the optimal allocation between the risk-free and risky assets. This is mainly a function of the investor’s risk aversion. In the second step, the risky assets are allocated across asset classes, ranging from seeking equally balanced risk exposures to opting for highly concentrated risk positions, particularly if the portfolio manager is highly skilled in forecasting. The goal here is to achieve market-level risk exposure while avoiding excessive concentration in systemic portfolio risks, typically starting from a value-weighted allocation within a targeted market. The third and final step involves the selection of specific stocks within these allocated asset classes, aiming to pick the most promising stocks. The overarching objective of this process is twofold: to minimize, or ideally eliminate, unrewarded idiosyncratic risk, and to strategically position the portfolio towards potentially rewarding systematic risk styles that offer collectible risk premia.
Active and passive investments coexist in a coherent way. While passive strategies are generally seen as efficient, they often come with high risk concentrations. The growing popularity of passive investments presents unique opportunities for active portfolio management. An investor lacking market insights or financial analysis skills can still achieve an efficient portfolio by simply investing in an index fund. However, the more this approach is adopted without proper analysis, the less likely it is that the market portfolio remains an efficient investment choice.
To illustrate the concept of diversification, consider a hypothetical homogeneous market where all assets have the same expected return 





Notably, the portfolio’s return remains constant regardless of
The portfolio’s variance is expressed as

This variance reduces to 

which is 
Since correlation is bound to ![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

which means that the portfolio risk cannot be higher than the weighted sum of the risk from the component securities. As soon as we add assets with 
This introduces the concept of the diversification ratio (Bodie et al. 2021), defined as

where 


1.1 The Risk-Free Asset
When we optimize a portfolio to achieve the highest possible risk-adjusted rate of return in excess to the risk-free rate, we are solving for the tangency portfolio. In this case the efficient frontier becomes the capital market line (CML), which spans a straight line between the risk-free rate of return and the mean-variance efficient frontier. At the tangency point, the slope of the CML is maximized, marking the point of the maximum Sharpe ratio portfolio. Along the CML we find optimal allocations of the tangency portfolio (risky asset) and the risk-free asset.
The return of the portfolio along the CML is defined by the equation

where 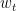

The portfolio risk is given by

Consequently, the weight of the tangency portfolio can be explicitly stated:

This is due to the zero variance of the risk-free asset and its lack of correlation with the tangency portfolio. Substituting this into the formula for portfolio return

and considering the following equation:

we derive the slope of the CML, synonymous with the Sharpe ratio, which is optimized in the tangency portfolio. An investor’s choice of the optimal point on the CML is influenced by their risk tolerance.
The concept of arbitrage is directly associated with the introduction of the risk-free asset. It is essential to both hedging and derivatives pricing. It means that if we are able to build a risk-free portfolio, in the case of two assets 






1.2 Utility
In his seminal 1952 work, Harry M. Markowitz introduced the portfolio selection problem, laying the groundwork for what is now known as the Modern Portfolio Theory (Sharpe et al. 1999). This theory and its derived Mean-Variance Optimization (MVO) approach have since become fundamental in crafting investment portfolios that align with an investor’s utility, or satisfaction, from their investments. The core of this theory is a formula that directly incorporates an investor’s risk tolerance:

In this equation, the expected return is offset by the portfolio’s variance, factoring in the investor’s risk aversion. Here, 
Our analysis employs the concept of maximizing utility across various risk aversion levels, including strategies like Kelly, Half Kelly, Market, and Trustee. We also explore other indices of investor satisfaction and objectives. These include optimizing for the highest return given a specific risk target, minimizing volatility for a given return target, aiming for the maximum Sharpe ratio (MSR), and constructing the maximum diversification portfolio (MDP). This comprehensive approach allows for a tailored investment strategy that best suits an investor’s individual risk-return preferences.
2 Factor Models
2.1 Market Model
Drawing from the insights of (Sharpe et al. 1999), the linear one-factor model stands as the most basic approach for linking asset returns with the movement of a common factor. In this model, the expected return of an asset

Here, 


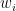
The variance of asset

where 



This model provides a necessary abstraction for the estimation of large covariance matrices, crucial for portfolio optimization, by assuming that asset correlations are primarily driven by their response to common factor movements. It presupposes that direct measurement of individual assets’ independent movements, i.e. idiosyncratic movement, is unnecessary if the factor model adequately captures systematic risk — the lower bound of portfolio risk and the only type of risk that yields rewards in financial markets.
Factor models are also instrumental in understanding diversification. They help analyze a portfolio’s risk exposure, distinguishing between factor risk and non-factor risk. On a portfolio level, this can be expressed as:

with the following equation detailing the specific components:

Diversification in a portfolio is achieved by including more assets with low correlation to the existing portfolio risk, thereby reducing the non-factor or idiosyncratic risk 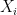



Here, 
2.2 The Capital Asset Pricing Model (CAPM)
The CAPM stands as a distinct economic equilibrium factor model, represented by the following formula:

Differing from general common factor models, which may incorporate multiple asset-specific characteristics, the CAPM uniquely features only one. A key distinction of the CAPM is that its intercept equals the risk-free rate, uniformly applicable across all assets. Contrastingly, in a common factor model, the intercept is an asset-specific measure, which is why such models don’t align with equilibrium asset pricing theories (Sharpe et al. 1999).
Our analysis focuses on examining the 

Upon visual assessment, it appears that the 

By incorporating the asset class-specific average 

This pattern of mean-reversion in market betas highlights a potential issue: the likelihood of overestimating future betas when current values are high, and underestimating them when they are low.
Figure 2 presents the rolling correlations between the residuals and the market factor. These correlations are expected to be near zero, yet we observe temporal interdependence. This suggests the presence of systematic risk factors that hold significance beyond the market factor.

2.3 Multi-Factor Models and the Arbitrage Pricing Theory (APT)
The APT qualifies as an economic equilibrium model like the CAPM and is utilized for predicting asset prices. Its general representation is:

In this model, 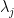

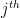
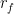
2.3.1 Fama/French 3 Factors
Originating from the Fama/French 3 factor model (Fama and French 1993), these factors include:

The factor data for the U.S. market is sourced from Kenneth R. French’s website at the Tuck School of Business, Dartmouth College.
2.3.2 Momentum Factor
This factor is derived from 2 x 3 sorted portfolios on size and previous 2-12 month returns (delayed by one month). The additional sort on the market cap is used to balance size effects in the momentum factor returns. It averages the returns from long high momentum and short low momentum positions. This data is also obtained from Kenneth R. French’s website.
2.3.3 Betting Against Beta (BAB)
The BAB factor highlights a unique connection between leverage constraints and the low beta risk premium (Frazzini and Pedersen 2013). This data is accessible from AQR Capital Management, LLC’s website.
Given our focus on a portfolio of just 10 sector index funds, we limit the number of factors to the Fama/French 3 factors plus momentum. The derivation of the covariance matrix of the S&P 500 on security level in then based on the same factor model plus the BAB factor.
Figure 3 illustrates the weekly return loadings to the Fama/French 3 factors plus momentum over time for the sector index funds.

In this multi-factor framework, the correlations between residuals and factors are essentially zero for all assets, while the variance of the residuals remains comparable to that in the CAPM. Moreover, the multi-factor model more accurately explains asset variance, as evidenced by the adjusted R-squared values.

The table above details the factor loadings for each asset class, with statistical significance denoted by: (***) for 



3 Approaches to Covariance Estimation
3.1 Covariance at the Security Level
Typically, the empirical sample mean and covariance are calculated as follows:

To better reflect the sequential character of financial returns, we modify these calculations by introducing exponential weights 

Similarly, the formula for exponentially weighted sample covariance is:

It’s important to note that with 
Meucci (2007) proposes estimating the optimal decay factor 
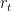

To find the log-likelihood’s maximum, the Nelder–Mead method, also known as the downhill simplex method, is frequently employed. This technique is relatively straightforward and useful for locating minima in multi-dimensional spaces, although it can be time-consuming due to its non-reliance on gradient evaluations.
In practice, a decay factor around 
3.2 Covariance Estimation at the Factor Level
The Arbitrage Pricing Theory (APT) represents a linear factor model, formulated as:

Here, 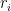



where 







Using this model, expected returns and the covariance matrix at the security level, influenced by common factors, are obtained from:

where ![\mu_f = \mathbb{E}[f]](https://s0.wp.com/latex.php?latex=%5Cmu_f+%3D+%5Cmathbb%7BE%7D%5Bf%5D&bg=ffffff&fg=000&s=0&c=20201002)

is the variance, split into the systematic factor risk and the idiosyncratic non-factor risk, the latter represented by the diagonal matrix
Our analysis employs weekly data for variance and covariance estimations. Bevan and Winkelmann (Bevan and Winckelmann 1998) recommend using daily returns over a five-year period to compute the covariance matrix. However, due to the low signal-to-noise ratio in daily returns, which offers limited long-term investor insight, we chose weekly returns.
We give an example for the calculation of a large covariance matrix for the S&P 500 Index constituents. We have estimated the covariances for 437 stocks (all stocks that have sufficient history over the sample period), yielding 

The correlation plot primarily indicates positive coefficients, aligning with the general tendency for stock returns to correlate positively. We employed hierarchical clustering to categorize co-moving assets, using the complete linkage method, which considers the euclidean distance between asset returns. In this method, groups are merged based on the maximum distance to other assets until all are unified. The number of rectangles corresponds to the number of common factors. The resulting groups, however, are not homogeneous, suggesting the presence of unexplained risk sources.
4 Mean-Variance Optimization
This section demonstrates the efficient frontiers of various portfolios, optimized based on:
- Different covariance estimates,
- Inclusion of uncorrelated assets, and
- Repeated bootstrapping of the same settings to assess estimate stability.
Each portfolio is optimized for minimum volatility across a range of target returns. We implement only the budget constraint and asset bounds between -1 and 1, allowing for potential leverage. The optimization process is initialized with equal asset weights
4.1 Analyzing Diverse Covariance Estimates
We utilize a variety of covariance estimates as detailed earlier, incorporating shrinkage techniques to enhance the robustness of these estimates against the low signal-to-noise ratio of asset returns. Notably, the efficient frontier varies considerably with each method. The exponentially weighted covariance (cov_ema) shifts leftward and steepens compared to the standard empirical covariance (cov_). The exponentially weighted factor covariance (cov_f_ema) also moves left but flattens, indicating a potential decrease in the Sharpe ratio. The frontier for the equal-weighted factor covariance (cov_f) closely resembles the standard empirical covariance (cov_).

The shrunken covariance is depicted separately due to its significantly lower overall variance. While not problematic for portfolio optimization, this results in exceedingly optimistic ex-ante target variance and Sharpe ratios, as illustrated in Table 1:

The shrunken covariance frontier (cov_lw), using Ledoit and Wolf’s (Ledoit and Wolf 2003) method, appears most advantageous, showing a steep slope and leftward shift. Conversely, the minimum covariance determinant (cov_mcd) approach sees the global minimum variance portfolio dominate, as the frontier extends almost linearly from it, implying minimal risk.
The optimal portfolio weights in percent for the different covariance estimates are shown in the following table 2.

The performance effects of a Maximum Sharpe Ratio (MSR) optimization are shown in Figure 6.

Table 3 reveals that the ex-post metrics are significantly lower than target values, with all Sharpe ratios falling below the market level (MCAP w).

While these performance figures aren’t definitive, as we derive expected returns based on historical returns (an unreliable method in portfolio optimization), an interesting observation is that flatter frontiers, like those from cov_f_ema and cov_mcd, tend to result in less volatile portfolios with higher Sharpe ratios.
4.2 Integrating Uncorrelated Assets
This section examines the impact of incorporating uncorrelated assets into portfolios to enhance diversification. Generally, diversification broadens the opportunity set, as depicted in Figure 7.

The table below highlights the target Sharpe ratio for each portfolio, utilizing empirical covariance matrices with both equal and exponential weightings. Notably, the Sharpe ratio improves with the addition of each new asset:

The portfolios, labeled ‘portf0’ through ‘portf4’, demonstrate progressive diversification by sequentially adding one asset at a time. The initial portfolio (portf0) comprises ten sector index funds. Subsequent additions include CMTY (portf1), TSY (portf2), GWT (portf3), and, for illustrative purposes, the BAB factor portfolio (portf4) due to its low correlation from the long-short payoff, although it’s not directly investable. Each addition of low-correlation assets significantly alters the efficient frontier, with the global minimum variance portfolio shifting leftward and downward. However, attaining a higher maximum Sharpe ratio typically requires short positions; otherwise, an increase in Sharpe ratio couldn’t be realize easily.
With portf4, we introduce the BAB factor portfolio, a long-short betting against beta strategy that is nearly uncorrelated with other assets. While not directly investable, a portfolio could be tilted towards this factor risk to capture the associated risk premium. This would involve analyzing the monotonicity of the factor returns and the theoretical turnover of the factor portfolio to assess potential rewards and costs of the style tilt. If the factor risk is consistently rewarded in the market, combining market-neutral factor exposure with passive market exposure could yield higher returns for reduced portfolio risk.
However, an example like the value factor (HML), which delivered a negative premium over the sample period, serves as a caution. Incorporating the HML factor wouldn’t enhance portfolio returns, but it would still shift the global minimum variance portfolio further left, showcasing the complex dynamics of factor-based diversification.
4.3 Stability Analysis through Bootstrapping
We investigate the stability of portfolio estimates using brute force bootstrapping, a method involving resampling observed asset returns with replacement.
In Figure 8, the bootstrapped efficient frontier for portf0 is displayed. With row-wise sampling the covariances between the assets and the expected returns per asset change with each sample. This exercise reveals a notable lack of robustness in the Mean-Variance Optimization (MVO) process.

Table 5 illustrates the maximum Sharpe ratio obtained from each bootstrap iteration. The varying shapes of the efficient frontier, coupled with fluctuating target returns and volatilities, cause the Sharpe ratio to range widely from 0.942 to 2.523. This variation highlights the substantial influence of the starting point and the sample period on allocations derived from mean-variance optimization.

An alternative approach is to fix the expected returns parameter in each sample to match historic returns. Figure 9 shows the resulting efficient frontier, which exhibits greater stability. The maximum Sharpe ratio in this scenario fluctuates within a narrower band of 1.174 to 1.741 (not shown in the table), indicating that expected returns might be a more critical parameter in MVO. However, the debate over the relative importance of expected returns versus covariances continues to be a contentious topic in financial literature (Ziemba 2016, Ledoit and Wolf 2003).

The efficient frontier can be made significantly more reliable by adopting a proper process for deriving the expected returns parameter vector. This approach will be further explored using the Black-Litterman model. A key takeaway from the Black-Litterman model is that unreasonable and unstable portfolio holdings often encountered in MVO are largely due to inconsistent and noisy forecasts of return and risk (Kolm and Ritter 2021).
4.4 Portfolio Optimization Across Various Satisfaction Metrics
In this section, we optimize portfolios for maximum utility, applying three distinct risk aversion profiles: Kelly (


The opportunity set is again reduced by the budget constraint an asset level bounds. We explore two asset level bounds scenarios: a liberal [-1,1] long-short asset level constraint, and a conservative [0, 0.25] long-only setting.
The portfolio weights obtained from the optimization are detailed in Table 6:

And for the more restrictive long-only setting in Table 7:

Noticeably, cornered solutions are prevalent, particularly in the long-only scenario with tighter asset bounds.
Table 8 highlights a notable decline in the diversification ratio when larger asset bounds are used. This suggests that the extent of diversification is largely influenced by the constraints imposed, dominating the actual process of asset selection. Relying on constraints for diversification often results in a significant reduction of the information utilized by the optimization process, which typically does not lead to optimal outcomes. The degree to which performance-related information is excluded can be quantified using the transfer coefficient (Grinold and Kahn 1999), which, in such cases, is expected to be lower than its potential maximum.

A backtested time series for a simple buy-and-hold strategy is illustrated in Figure 10:

The unconstrained Kelly portfolio in case A (left-hand diagram) suits risk-seeking investors desiring lottery-like payoff profiles. However, its extreme volatility, characterized by significant gains followed by crashes, makes it impractical for most investors. The Trustee portfolio, tailored for high risk aversion and capital preservation, underperforms the market average over the sample period. The Market portfolio, aiming for risk exposure proportional to an investor’s total wealth, aligns closely with the MSR portfolio, the tangency portfolio with the highest CML slope. Surprisingly, the MDP, despite its allowance for short sales and focus on diversification, exhibits market-level drawdowns and underperforms. Investors are familiar with the fact that assets become highly correlated in a stressed market environment, and correlations shrink when markets recover. This portfolio has weak returns in both periods – at least in the short run. However, in the highly uncertain market of 2022, marked by geopolitical tensions and economic crisis, the MDP performs pretty well.
With the tighter constraints in case B (right-hand diagram), narrow asset bounds and long-only, the Kelly portfolio looks more interesting as it becomes less volatile, while the Market and the MSR portfolios temporarily perform below the value-weighted market average. However, as outlined above, setting tighter constraints is always a hard cut in the process of portfolio construction and does not lead to optimal solutions in general.
In case B (right-hand diagram), with tighter asset bounds and long-only constraints, the Kelly portfolio becomes less volatile and more appealing, while the Market and MSR portfolios occasionally fall below the market average. However, as previously mentioned, imposing tighter constraints often leads to suboptimal portfolio construction. This underscores the need for a more comprehensive approach to risk management in the modeling process, rather than simply restricting positions.
5 Implementing the Black-Litterman Model
We will adhere to a five-step framework for constructing the Black-Litterman (BL) model, a Bayesian approach:

Once implemented, we’ll revisit the portfolio selection issue to see how the reliability of Mean-Variance Optimization (MVO) is enhanced through the BL model.
Step 0: Understanding Bayes’ Theorem
Bayes’ theorem is a fundamental tool for updating probability assessments with new information:

This concept is mathematically represented as:

where 

Bayes’ theorem is essentially derived from the principle of probability multiplication:

In Bayesian terminology, we interpret the components as follows:
is the prior probability, representing the initial, uninformed probability of event
is the posterior probability, reflecting the probability of event
functions as a normalization factor.
is the likelihood function.
The key idea is that Bayesian investors make investment decisions based on their confidence in return estimates. Rather than relying solely on fixed point estimates, investors define their expectations as distributions that are continuously updated with emerging information.
Step 1: Reverse optimization to establish prior beliefs
In the Black-Litterman (BL) framework, the first step involves determining the prior distribution, which serves as our baseline market perspective. Ideally, this prior should reflect a neutral market view, yet typical choices like an equal weighted portfolio or a global minimum variance portfolio have limitations. An equal weighted portfolio doesn’t effectively establish a prior view of excess returns, and constructing a global minimum variance portfolio inadvertently relies on historical returns, failing to represent future expectations.
The solution to this problem by Black and Litterman (ibid. 1991, 1992) is both, effective and elegant: they apply the equilibrium CAPM portfolio, which is the tangency portfolio, to obtain the expected excess returns given the investor’s average risk aversion and level of market risk. The resultant vector is assumed to be the market-clearing return vector.
We begin with the mean-variance optimization problem

to get the prior excess return, where 
The first derivative (necessary) with respect to 
 The second derivative (sufficient) confirms the maximization:
The second derivative (sufficient) confirms the maximization:

If we now assume that the CAPM holds, i.e. markets are (broadly) in equilibrium, then we can reverse engineer the equilibrium vector of excess returns 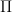

where 

To obtain the implied equilibrium return vector 

where, 


The Sharpe ratio 


In reverse optimization,
The equilibrium excess return vector

which represents the first moment of the prior distribution for the excess return

where 


We can therefore rewrite the prior distribution of excess returns as follows

Unfortunately there is no clear guidance on how to chose 

Step 2: Impute investor’s views
The Black-Litterman (BL) model’s strength lies in its ability to integrate the views of analysts and portfolio managers, thereby refining expected return estimates and asset allocation. We introduce three distinct investor views:
We formulate three different views:
- View 1 (absolute): TECH is expected to yield an absolute return of 16% (confidence = 75%). The implied equilibrium excess return
for TECH is 8.51%, which is 749 basis points below our view — we anticipate the model will increase TECH’s portfolio weight.
- View 2 (absolute): HC is anticipated to yield 13% absolute (confidence = 80%). For HC we obtain a
- View 3 (relative): Cyclical sectors (CDIS, IND, FIN, TECH, MAT) are projected to outperform defensive sectors (CSTP, EGY, HC, UTL) (Sector assignments to cyclical and defensive are made on the basis of MSCI definitions.) by 5% (confidence = 70%). The formulation of this view is more intuitive for financial markets professionals. Multiple of assets are involved, where the number of outperforming assets does not have to match the number of underperforming assets. We have to apply a relative weighting scheme: The outperforming cyclical sectors have relative market cap weights of
,
,
,
and
, and the implied equilibrium excess returns for the sectors are given by
,
,
,
and
respectively. For the underperforming defensive sectors have relative market cap weights of
,
,
and
, and the implied equilibrium excess returns for the sectors are given by
,
,
and
respectively. Hence, we have (9.73% x 19.90% + 9.76% x 16.68% + 12.96% x 23.47% + 8.51% x 33.38% + 9.87% x 6.56%) – (4.93% x 28.69% + 9.87% x 16.64% + 6.47% x 42.62% + 4.91% x 12.05%) = 24.65%, which is much greater than the 5% stated in view 3. Consequently, the model is likely to adjust by reducing weights in cyclical sectors in favor of defensive ones.
We represent these views in a matrix 
The Real Estate (RE) sector fund is intentionally left unaffected by these views, and we expect it to maintain market-level weights.
The returns associated with these views are captured in a vector 


The matrix 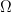
Step 3: Constructing the posterior distribution
The expected returns resulting from the BL model are essentially a confidence-weighted blend of the market-implied expected returns and the investor’s specific views (Kolm and Ritter 2021). This process involves:
We have got
- The prior equilibrium distribution, symbolized as
, representing the probability
- The conditional distribution of our views given this prior, denoted as
In applying Bayes’ Theorem to continuous distributions, the normalizing constant
By integrating the prior and the conditional distributions using Bayes’ Theorem, we derive the new (posterior) return distribution:

which gives us the most important information about the posterior expected excess return, given in the Black-Litterman formula:

In scenarios of 100% confidence, i.e. 

Conversely, when uncertainty is extremely high, i.e. 

Finally, Table 10 allows us to compare the adjusted expected excess returns and portfolio weights:

As expected, there is a noticeable shift toward TECH and HC, in line with views 1 and 2. In view 3, the cyclical sectors were predicted to outperform the defensive sectors, but the magnitude of outperformance was estimated lower than the differential from the value-weighted aggregates of the implied excess expected returns would suggest. Therefore, cyclical sectors receive lower weights in favor for defensive sectors. Even the conflicting views 1 and 3 are processed accordingly and the BL model yields reasonable weights for the cyclical TECH sector.
RE, deliberately excluded from the views, demonstrates another major strength of the BL model: allocation changes occur only in response to expressed views. Hence, the weight difference for RE is null, as shown in the final column.
The new portfolio composition effectively combines the original market capitalization-weighted portfolio with a series of long-short positions emanating from the investor’s views. The resulting return vector ![E[R]](https://s0.wp.com/latex.php?latex=E%5BR%5D&bg=ffffff&fg=000&s=0&c=20201002)
5.4.1 Fine Tuning the Model
The model’s effectiveness can be enhanced by carefully analyzing the characteristics of the new combined return vector
Additionally, the augmented model proposed by Qian and Gorman (2001) permits incorporating views on volatilities and correlations. This approach allows for obtaining a conditional estimate of the covariance matrix of returns, further refining the model’s predictive capability and accuracy.
5.4.2 Incorporating Confidence – An intuitive approach
Up to now, we have not fully incorporated the stated confidence levels associated with the three views we discussed. Thanks to Idzorek’s extension of the BL model (ibid. 2004), it’s possible to integrate the confidence matrix
We approximate the tilt towards a specific view 

where 

where 
We have to solve for the posterior expected excess return twice: firstly, for 
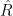
Idzorek suggests a least squares optimization method to compute the confidence matrix


where

A step-by-step guide is given by Idzorek (2004) for this process. However, there is also a closed-form solution available (Walters 2014), which we will employ in our subsequent analysis. This approach allows for a more streamlined integration of confidence levels into the BL model, enhancing its practicality and relevance.
5.4.3 Closed-form solution
For Idzorek’s extension of the Black-Litterman model, a more straightforward analytical solution is available, as presented by Walters (2014). This solution accommodates investor confidence on a scale ranging from 0% to 100%. The shift in portfolio weights from the prior to the posterior, under a specific view, can be linearly represented as:

where 

The uncertainty associated with each view is defined as:

In this context, 

We can substitute (53) into the alternate form of (47), which is given in Meucci (2010) as

we obtain:

This can then be integrated into the formula for 

By resolving equation (56) for

And rewriting certain terms in (56), we arrive at:

Subsequently, substituting

Comparing this with equation (53), we deduce:

Ultimately, this gives us:

Using the same views previously mentioned, with confidence levels at 75% for view 1, 80% for view 2, and 70% for view 3, the outcomes are displayed in Table 11. Notably, high confidence levels cause the weights to become more pronounced. The most significant influence arises from views 1 and 2, where the investor’s return expectation is both highly confident and substantially divergent from the market’s implied excess expected return.

Step 4: Asset allocation
Using the BL model, we now proceed to asset allocation tailored to different risk preferences. We compare the approaches for Kelly, Market, and Trustee investors, as shown in Table 12. For the Kelly investor, with minimal risk aversion (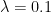


The performance of these varied BL portfolios is a function of the risk aversion parameter, primarily affecting leverage or the remaining cash balance. Normalizing the associated time series would reveal identical trends, as the diversification ratio, shown in Table 13, remains constant across different levels of risk aversion. Therefore, adjusting the

5.6 Portfolio Selection
We proceed to utilize the combined return vector


The portfolio weights, under both sets of asset bounds (Tables 14 and 15), remain fairly consistent, with notable changes primarily in the Kelly portfolio. This aligns with expectations given the Kelly strategy’s minimal risk aversion and propensity for extreme asset weights. On the other hand, the Trustee portfolio appears more influenced by asset level restrictions, showing a pronounced preference for the comparatively low-risk Consumer Staples (CSTP) sector when unconstrained. In contrast, in the Kelly portfolio, defensive sectors such as Consumer Staples (CSTP) and Utilities (UTL) are assigned negative weights, indicating a shift towards sectors with potentially higher returns. Overall, this optimization round has shown improved stability over previous versions. Notably, the weights in the Maximum Sharpe Ratio (MSR) portfolio display lower variability, with adjustments in the Technology (TECH), Healthcare (HC) and Consumer Staples (CSTP) sectors.
Performance metrics for these optimized portfolios are summarized in Table 16.

Before discussing the detailed performance figures, it is crucial to note that these outcomes are based on a buy-and-hold strategy without rebalancing and maintaining fixed views over a three-year period. The Black-Litterman (BL) model’s systematic integration of investor views stands out for its potential to enhance performance, especially when these views are accurate. However, caution is warranted in placing too much emphasis on these metrics.
The Kelly portfolio emerges as particularly beneficial, generating an active return of 1.1% per annum alongside an Information Ratio of 0.601. This portfolio features a relatively modest tracking error of 2.1%, which is lower compared to other portfolios where active risk levels vary from 3.0% to 8.5%. Its market beta is around 1, suggesting it does not take on excess market risk, and it yields a Jensen’s Alpha of 1.1%, marking returns that exceed those predicted by the Capital Asset Pricing Model (CAPM) – a critical objective for active portfolio management. Additionally, the Kelly portfolio adheres to market-level maximum drawdowns, with both the average duration and recovery times of these drawdowns aligning closely with the market benchmark.
Performance charts are presented in Figure 12.

Figure 13 illustrates the variation in asset weights along the efficient frontier. Here, the BL model, based on the combined return expectations

Diversification ratios for each index of satisfaction, shown in Table 17, exhibit some variation. However, diversification remains relatively consistent across different asset bounds. The optimization process has become more stable, with constraints exerting significantly less impact on portfolio selection.

5.7 Performance Attribution
We show the performance attribution for the case B portfolios with the asset level bounds of [-0.03,0.25]. As shown in Figure 14, the attribution analysis identifies the contributions of common factors, specific risk, tilts, and timing to the total returns of the portfolio. The common factors encompass the market return over the risk-free rate (Mkt-RF), Size (SMB), Value (HML), and Momentum (MOM). Returns from tilts are calculated as the average exposure to factor risks multiplied by the returns of those factors. Timing returns are the common returns minus the tilt returns, and specific returns are the returns of the portfolio after subtracting the common returns. It is important to note that portfolio return contributions are mainly from common factors and tilts in all portfolios.
Up to 2022, the Kelly portfolio stood out for its high contributions from common factors and tilts compared to other portfolios, yet its returns were nearly identical to those of the value-weighted benchmark portfolio. During the same period, specific contributions were negative across all portfolios, with the exception of the Maximum Diversification Portfolio (MDP), which showed negligible changes. Following the market downturn in 2022, contributions from common factors and tilts fell in all portfolios, but the MDP demonstrated its diversification strengths by exhibiting the smallest decrease in common factor returns. Conversely, specific returns saw an increase, most notably in the Trustee portfolio. Additionally, timing contributions also dropped during this period, especially in portfolios where the CAPM beta significantly deviated from 1.

In Figure 15, the factor risk exposures across most portfolios are fairly similar. There’s a clear positive exposure to the market (Mkt-RF), while Size (SMB) shows negative exposure. Value (HML) is often neutral for all portfolios, but when it’s not, it tends to be negative. On the other hand, Momentum (MOM) generally follows a pattern of neutrality, but when it diverges, it’s more likely to be positive. In the Maximum Diversification Portfolio (MDP), the factor contributions are more balanced. The market factor is still the strongest influence, but the negative impact of SMB is reduced, and both HML and MOM are less neutral.

5.8 Views on Factors
The BL model is not directly applicable to impute views on factor performance. A factor itself is a relative view on the performance of assets. However, we can implement an extension by Kolm and Ritter (2016, 2021) to the BL model that allows to process views on factors directly.
We know that

where ![\mu_f = \mathbb{E}[f_t]](https://s0.wp.com/latex.php?latex=%5Cmu_f+%3D+%5Cmathbb%7BE%7D%5Bf_t%5D&bg=ffffff&fg=000&s=0&c=20201002)
![F_t = \mathbb{V}[f_t]](https://s0.wp.com/latex.php?latex=F_t+%3D+%5Cmathbb%7BV%7D%5Bf_t%5D&bg=ffffff&fg=000&s=0&c=20201002)
The authors identify two types of priors for factor premiums, a data driven prior, suitable for absolute return strategies, and a benchmark prior.
5.8.1 Data driven prior
The data driven prior can be obtained by the estimates of the OLS

where 
5.8.2 Benchmark driven prior
The benchmark driven prior is given by

where 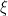


The BL expected returns and covariance matrix for factor portfolios is obtained by

where 


5.9 Remarks on the performance of the BL model
The performance of the BL model can only be as good as the views that are expressed on future asset or factor returns. This is where various sources of forecasts can come in, e.g.
- Consensus market estimates from large asset managers
- Forecasts from machine learning agents and artificial intelligence
- Multi-factor models
- Discretionary predictions from a portfolio manager in the form of relative views, like cyclical vs. defensive
We have seen that there are various ways to define confidence, like e.g. a discretionary figure, the variance of the views, or the variance of the residuals in a multi-factor setting. Each use case needs to be tailored. However, the BL model is a flexible framework that suits to a broad range of use cases. Also, the views do not have to be point estimates but can also be directional classes like ‘bullish’, ‘neutral’ and ‘bearish’, or with the use of several subclasses, e.g. ‘very bullish’, ‘bullish’, and so on.
6 Concepts and Methods
Table of user defined functions from first principles:

Adapted functions and methods from Python:

Adapted functions and methods from R:

References
Beach, Steve L. and Alexei G. Orlov, 2007. “An Application of the Black-Litterman Model with EGARCH-M-Derived Views for International Portfolio Management.”, In: Financial Markets and Portfolio Management.
Bevan, Andrew and Kurt Winkelmann, 1998. “Using the Black-Litterman Global Asset Allocation Model. Three Years of Practical Experience.”, In: Global Fixed Income Portfolio Strategy, Fixed Income Research, Goldman, Sachs Co.
Black, Fischer and Robert Litterman, 1991. “Global Asset Allocation with Equities, Bonds, and Currencies.” In: Global Fixed Income Portfolio Strategy, Fixed Income Research, Goldman, Sachs Co.
Black, Fischer and Robert Litterman, 1992. “Global Portfolio Optimization.”, In: Financial Analysts Journal, Sep/Oct 1992, 48, 5, pp. 28-43.
Bodie, Zvi, Alex Kane, and Alan J. Marcus, 2021. “Investments”, 12th International Edition. McGraw-Hill.
Campbell, John Y., Andrew W. Lo, and A. Craig MacKinlay, 1997. “The Econometrics of Financial Markets.”, Princeton University Press.
Cornuéjols, Gérard, Javier Peña, and Reha Tütüncü, 2018. “Optimization Methods in Finance.”, Second Edition. Cambridge University Press.
Efron, Bradley and Carl Morris, 1997. “Stein’s Paradox in Statistics.”, In: Scientific American, 236(5), pp. 119–27.
Ehsani, Sina and Juhani Linnainmaa, 2020. “Factor Momentum and the Momentum Factor.”, In: SSRN-id3014521.
Fama, Eugene F. and Kenneth R. French, 1993. “Common Risk Factors in the Returns on Stocks and Bonds.”, In: Journal of Financial Economics 33, pp. 3-56.
Frazzini, Andrea and Lasse Heje Pedersen, 2013. “Betting Against Beta.”, In: Journal of Financial Economics.
Grinold, Richard C. and Ronald N. Kahn. “Active Portfolio Management. A Quantitative Approach for Producing Superior Returns and Controlling Risk.”, Second Edition. McGraw-Hill.
Grinold, Richard C. and Ronald N. Kahn, 2020. “Advances in Active Portfolio Management. New Developments in Quantitative Investing.”, McGraw-Hill.
He, Guangliang and Robert Litterman. 2002. “The Intuition Behind Black-Litterman Model Portfolios.”, In: SSRN-id334304.
Idzorek, Thomas M., 2004. “A Step-By-Step Guide to the Black-Litterman Model. Incorporating User-Specified Confidence Intervals.”, In: Zephyr Associates.
Ingersoll Jr., Jonathan E., 2021. “Theory of Financial Decision Making.”, Dev Publishers & Distributors.
Kolm, Petter N. and Gordon Ritter, 2016. “On the Bayesian Interpretation of Black-Litterman.”, In: SSRN-id2853158.
Kolm, Petter N. and Gordon Ritter, 2021. “Factor Investing with Black-Litterman-Bayes. Incorporating Factor Views and Priors in Portfolio Construction.”, In: The Journal of Portfolio Management. Quantitative Special Issue. pp. 113-26.
Laloux, Laurent, Pierre Cizeau, Marc Potters, and Jean-Philippe Bouchaud, 2000. “Random Matrix Theory and Financial Correlations.”, In: International Journal of Theoretical and Applied Finance, Vol.3, No.3, pp. 391-97.
Ledoit, Olivier and Michael Wolf, 2003. “Improved Estimation of the Covariance Matrix of Stock Returns with an Application to Portfolio Selection.”, In: Journal of Empirical Finance, 10, pp. 603-21.
Meucci, Attilio, 2007. “Risk and Asset Allocation.”, Springer Finance.
Meucci, Attilio, 2009. “Enhancing the Black-Litterman and Related Approaches. Views and Stress-Test on Risk Factors.”, In: SSRN-id1213323.
Meucci, Attilio, 2010. “The Black-Litterman Approach. Original Model and Extensions.”, In: SSRN-id1117574.
Qian, Edward and Stephen Gorman, 2001. “Conditional Distribution in Portfolio Theory.”, In: Financial Analyst Journal 57, pp.44-51.
Sharpe, William F., Gordon J. Alexander, and Jeffery V. Bailey, 1999. “Investments”, 6th International Edition. Prentice-Hall International, Inc.
Walters, Jay, 2014. “The Black-Litterman Model in Detail.”, In: blacklitterman.org.
Ziemba, Wiliam T., 2016. “An approach to financial planning of retirement pensions with scenario dependent correlation matrices and convex risk measures.”, In: Journal of Retirement, Summer 1-13.