This report delves into the intricate world of Monte Carlo simulations for option pricing. Focusing on types of Asian, Lookback, and Binary options, we explore the method based on the application of Geometric Brownian Motion. We scrutinize various random number generation methods, including the Box-Muller transformation and Halton sequences, assessing their impact on the precision of simulations. The report also contrasts the Euler-Maruyama and Milstein schemes as approximations to closed-form solutions, underlining their relevance in practical option pricing scenarios. This comprehensive study aims to provide a deep understanding of the nuances and challenges in Monte Carlo methods for pricing financial derivatives.
Introduction
Monte Carlo simulations are instrumental in numerical integration, particularly in scenarios where i) we want 


![\mathbb{E}[\cdot] \to \int_{\mathbb{R}} f(x)\;dx](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Ccdot%5D+%5Cto+%5Cint_%7B%5Cmathbb%7BR%7D%7D+f%28x%29%5C%3Bdx&bg=ffffff&fg=000&s=0&c=20201002)
$$V(S,t) = e^{-r(T-t)} \mathbb{E}^{\mathbb{Q}}\text{[Payoff]}.$$
These simulations are based on Geometric Brownian Motion to model future states of the underlying asset, thus every single iteration represents a random and independent realization of the asset price in the future. Monte Carlo methods are flexible and widely used in computational finance for pricing financial derivatives, and often the first approach to model exotic payoffs. We will use it to price path-independent Binary options and path-dependent Asian and Lookback options.
A key aspect of these simulations is the martingale approach in option pricing, emphasizing the equality of future value expectations to their current value ![\mathbb{E}[S_i|S_j,j<i]=S_j](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BS_i%7CS_j%2Cj%3Ci%5D%3DS_j&bg=ffffff&fg=000&s=0&c=20201002)
Advantages of Monte Carlo Simulations
The main advantage of Monte Carlo simulation is that we do not have to know the underlying distribution of the functional variables of interest, thanks to the method’s reliance on on random processes like Geometric Brownian Motion.
Monte Carlo methods are useful for pricing strongly path dependent options and to solve high dimensional problems. Asian and Lookback options are strongly path dependent. We will see that this property leads to a three-dimensional problem, where we have to track an additional independent variable beside the time 


Challenges and Limitations
The main disadvantage of Monte Carlo as a numerical method is that it can be complex to calculate option sensitivities (Greeks), since they cannot simply be derived from the pricing procedure, like from the Black-Scholes-Merton equation. Monte Carlo simulation is also generally limited to European style options without embedded decisions, though certain adaptations exist for American options (Boyle, Broadie, Glasserman 1997).
Standard Monte Carlo methods require lots of computational resources and can be very inefficient, in particular for deep-out-the money European options, where most simulated paths end up with a zero payoff and provide no additional information to the option’s value. However, variance reduction techniques can mitigate this issue. In practice, Monte Carlo methods are often used as a starting point to price a specific contract type, while in production, the method of choice is commonly finite difference, which is much faster than Monte Carlo.
We want to use Monte Carlo to price options with more than three dimensions and path dependent options (even in low dimensions). We don’t want do utilize standard Monte Carlo for contracts with embedded decisions.
Project Focus
Our study will delve into the pricing of Binary, Asian, and Lookback call options using Monte Carlo methods, with a specific focus on the accuracy and sampling error of these simulations. We aim to determine the requisite number of simulations for adequate accuracy and the necessary reduction in timestep size to minimize sampling errors.
Geometric Brownian Motion
We will explore how stock price behavior is mathematically described by Geometric Brownian Motion. This involves manipulating a stochastic differential equation (SDE) to represent stock price dynamics. We start with the general form of an SDE for 
$$dG = a(G,t) \; dt + b(G,t) \; dX$$
The SDE denotes a stochastic process 



We know that 
\begin{equation*} G_t = g_0 + \int_{0}^{t} a(G_s,s)\;ds + \int_{0}^{t} b(G,s)\;dX_s \end{equation*}
In this context, the expected value of 
\begin{equation*} \mathbb{E}[a\;dt] + \mathbb{E}[b\;dX] = a\;dt + b\; \mathbb{E}[dX] = a\;dt, \end{equation*}
where the expected value of 
Furthermore, the variance of this term is given by:
\begin{equation*} \mathbb{V}[a\;dt] + b^2\; \mathbb{V}[dX] = 0 + b^2 \; dt = b^2 \; dt \end{equation*}
This result is obtained considering that the variance of a constant (scalar) is zero and taking into account that the variance of 
When we apply a random walk defined by the equation
$$dS = \mu S \;dt + \sigma S \; dX$$
it is commonly reformulated as:
\begin{equation*} \frac{dS}{S} = \mu \; dt + \sigma \; dX \end{equation*}
In this context, we have set 


To analyze the variation in a function 





$$df = \frac{df}{dX} dX + \frac{1}{2} \frac{d^2 f}{dX^2} dt$$
The expansion aligns with Itô’s lemma when we consider the limit 
Extending this concept to the valuation of an option price 




Our focus is on how the value of the option, 

\begin{equation*} V(S+dS) = V(S) + \frac{dV}{dS} dS + \frac{1}{2} \frac{d^2 V}{dS^2} dS^2 \end{equation*}
By rearranging this expression and bringing 
\begin{equation*} dV = \frac{dV}{dS} dS + \frac{1}{2} \frac{d^2 V}{dS^2} dS^2 \end{equation*}
As we approach the limit 

\begin{equation*} dS^2 = \mu^2 S^2 dt^2 + 2 \mu S^2 dt dX + \sigma^2 S^2 dX^2 = 0 + 0 + \sigma^2 S^2 dt = \sigma^2 S^2 dt \end{equation*}
With the formula for
$$dV = (\mu S \frac{dV}{dS} + \frac{1}{2} \sigma^2 S^2 \frac{d^2 V}{dS^2})\; dt + (\sigma S \frac{dV}{dS}) \; dX$$
representing an SDE with a predictable drift and a random diffusion term.
A particularly significant step in financial applications is setting 

\begin{equation*} \frac{dV}{dS} = \frac{1}{S}. \end{equation*}
Further differentiation yields the second derivative:
\begin{equation*} \frac{d^2 V}{dS^2} = -\frac{1}{S^2} \end{equation*}
These derivatives are crucial in the application of Itô’s lemma to financial models.
Incorporating the previously determined derivatives into Itô’s lemma (III), we arrive at a standard transformation. This transformation is recognized as the Cauchy-Euler equation, which is a constant coefficient problem, where both
\begin{equation*} dV = d(log S) = [\ \mu S \frac{1}{S} + \frac{1}{2} \sigma^2 S^2(-\frac{1}{S^2})]\ \; dt + \sigma S \frac{1}{S} \; dX = (\mu – \frac{1}{2} \sigma^2)\; dt + \sigma \; dX \end{equation*}
Thus, from this equation, we derive:
\begin{equation*} d(log S) = (\mu – \frac{1}{2} \sigma^2) \; dt + \sigma \; dX. \end{equation*}
This expression represents a simplified form of the stochastic differential equation for the logarithm of the stock price
Integrating both sides of the equation from the current time (0) to a future time (t), we obtain:
\begin{equation*} \int_{0}^{t} d(log S) = \int_{0}^{t} (\mu – \frac{1}{2} \sigma^2) \; d \tau + \int_{0}^{t} \sigma \; dX = (\mu – \frac{1}{2} \sigma^2) \; t + \sigma (X(t) – X(0)) \end{equation*}
Assuming 

$$S(t) = S_0 e^{(\mu – \frac{1}{2} \sigma^2) \; t + \sigma X(t)}$$
Similarly, for a small time increment from
\begin{equation*} S_{t+dt} = S_t e^{(\mu – \frac{1}{2} \sigma^2)\;dt + \sigma \phi \sqrt{dt}} \end{equation*}
where 



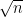

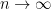
As already stated above, under the risk-neutral measure 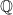

Approximations to the closed form solution
In many financial applications, a closed-form solution may not be readily available or even feasible. Hence, approximation methods like the Euler-Maruyama and Milstein schemes are employed, which offer known error bounds.
Euler-Maruyama
We can use the Euler-Maruyama scheme as a first (basic) order approximation for the given SDE, which we consider here in the more general form as
$$dX_t = a(X_t,t)dt + b(X_t,t)dW_t.$$
Integrating both sides over an interval 
\begin{equation*} \int_{t_n}^{t_{n+1}} dX_s = \int_{t_n}^{t_{n+1}} a(X_s,s)\;ds + \int_{t_n}^{t_{n+1}} b(X_s,s)\;dW_s \ X_{n+1} = X_n + \int_{t_n}^{t_{n+1}} a(X_s,s)\;ds + \int_{t_n}^{t_{n+1}} b(X_s,s)\;dW_s \end{equation*}
Applying the left hand integration rule, we extract 


\begin{equation*} \int_{t_n}^{t_{n+1}} a(s,X_s)\;ds = a(t_n,X_n) \int_{t_n}^{t_{n+1}} ds = a(t_n,X_n)\; \delta t \ \int_{t_n}^{t_{n+1}} b(s,X_s)\;dW_s = b(t_n,X_n) \int_{t_n}^{t_{n+1}} dW_s = b(t_n,X_n)\Delta W_n \end{equation*}
Here, 

\begin{equation*} X_{n+1} = X_n + a(t_n,X_n)\; \delta t + b(t_n,X_n)\Delta W_n. \end{equation*}
For Geometric Brownian Motion (GBM), the Euler-Maruyama scheme yields:
\begin{equation*} \frac{\delta S_t}{S_t} = \frac{S_{t+\delta t}-S_t}{S_t} \sim r \delta t + \sigma \phi \sqrt{\delta t} \end{equation*}
i.e.
\begin{equation*} S_{t+\delta t} \sim S_t (1 + r \delta t + \sigma \phi \sqrt{\delta t}). \end{equation*}
This approximation has an accuracy of 
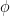
Milstein scheme
The Milstein scheme, derived from a Taylor series expansion (Itô’s lemma), builds upon the exact closed-form solution of the stochastic differential equation. Considering the expansion of 
\begin{equation*} e^{(r \;-\; \frac{1}{2} \sigma^2)\;\delta t \;+\; \sigma \phi \sqrt{\delta t}} \sim 1 + (r – \frac{1}{2} \sigma^2) \;\delta t + \sigma \phi \sqrt{\delta t} + \frac{1}{2} \sigma^2 \phi^2 \delta t \end{equation*}
which leads to the approximation:
\begin{equation*} S_{t+\delta t} \sim S_t(1 + r \delta t + \sigma \phi \sqrt{\delta t} + \frac{1}{2} \sigma^2 (\phi^2-1) \delta t + \dots) \end{equation*}
This expression represents the Euler-Maruyama scheme with an added term, 

$$S_{t+\delta t} = S_t (1 + (r + \frac{1}{2} \sigma^2 [\phi^2-1])\;\delta t + \sigma \phi \sqrt{\delta t}).$$
The accuracy of the Milstein scheme in terms of Geometric Brownian Motion is of order 
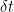

It is crucial to note that both instances of
Pseudo-Random Number Generation in Monte Carlo Simulations
The efficacy of Monte Carlo simulations heavily relies on the quality of the random number generator used. These generators, often transforming uniform distributions into Gaussian distributions, are vital yet inherently imperfect, as they produce sequences that only approximate randomness. These sequences are known as pseudo-random numbers due to their underlying deterministic nature and inevitable periodicity – the point at which the sequence begins to repeat itself. This characteristic was highlighted by Knuth (1969), who noted that even the best generators eventually exhibit repetition. Optimal generators are characterized by a lack of serial autocorrelation and an extended period before repetition. Historically, the development of reliable random number generators has been crucial for the advancement of Monte Carlo methods, with the strength of a simulation being contingent on its weakest component (Jäckel 2002:67 ff., Wilmott 2006:1268).
Generating Random Numbers with the Box-Muller Transformation
We demonstrate the generation of Gaussian-distributed random numbers using the Box-Muller transformation (specifically Marsaglia’s polar method). This process begins by generating uniform random numbers within the range [0,1] and subsequently converting these into Gaussian distributions.
Implementation of Halton Sequences
In addition to the Box-Muller method, we have implemented Halton sequences, which fall into the category of low discrepancy or quasi-random numbers. These sequences are particularly useful in accelerating the convergence of Monte Carlo simulations. The advantage of Halton sequences lies in their more even distribution compared to pseudo-random numbers, making them less random and thus more effective, especially in higher-dimensional problems.
Comparison with Standard Normal Method in Numpy
We also utilize the standard normal method from the Numpy package to generate random numbers. In our comparative analysis, we observe minor differences between the standardized random numbers from Numpy and those generated via the Box-Muller method. Altering the seed reveals that sometimes one method and sometimes the other more closely aligns with the standard normal density curve. As the sample size

In practical applications, it is advisable to maintain a varied collection of random number generators. This diversity allows for flexibility in simulations, enabling switching between different methods or altering seeds within a single method, thereby enhancing the robustness of the results (Jäckel 2002:75).
Analyzing Autocorrelations in Random Number Sequences
Upon visually inspecting autocorrelation patterns across 2,000 time lags, no significant differences are discernible between the various methods. However, this observation is subject to change upon altering the seed and re-executing the analysis. It’s noted that these methods occasionally exhibit varying degrees of outliers. Halton sequences, inherently defined by their structure, exhibit notable autocorrelations. This characteristic becomes particularly evident in time series plots or autocorrelation analyses, especially if the sequence isn’t randomized through shuffling prior to analysis. The autocorrelation diagrams include a significance level, demarcated by a bandwidth, set at 1%. This threshold helps in identifying significant autocorrelations within the generated sequences.

Enhancing Variance Reduction in Random Number Generation
The use of algorithmically generated random numbers often leads to deviations from the expected first and second moments (mean and standard deviation) of the standard normal distribution. This misalignment is evident when observing that the sample means are not zero and the standard deviations are not one:
for i in range(1, 11):
random.seed(10000)
sn = random.standard_normal(i**2*10000)
print("%15.12f %15.12f" % (sn.mean(), sn.std()))
To address these discrepancies, techniques such as antithetic variates and moment matching can be employed.
Antithetic Variates for Variance Reduction
Antithetic variates are a variance reduction technique that introduces negative dependence between pairs of random numbers. This method involves taking half of the random draws, inverting their sign (resulting in 
# Antithetic Variates:
for i in range(1, 11):
random.seed(10000)
sn = random.standard_normal(int(i**2*10000/2))
sna = concatenate((sn,-sn), axis=0)
print("%15.12f %15.12f" % (sna.mean(), sna.std()))
Despite this adjustment, the sample standard deviations may still not align with the ideal value of one.
Moment Matching Technique
Moment matching directly adjusts each random number by subtracting the sample mean and dividing by the sample standard deviation. This straightforward method effectively aligns the distribution of random numbers with the first and second moments of the standard normal distribution, achieving near-perfect matching.
# Moment Matching:
for i in range(1, 11):
random.seed(10000)
sn = random.standard_normal(int(i**2*10000/2))
sn = (sn - sn.mean())/sn.std()
print("%15.12f %15.12f" % (sn.mean(), sn.std()))
The application of the antithetic variates technique can significantly enhance the convergence speed and accuracy of simulations. This method is versatile and can be applied across various pricing tasks in financial modeling.
Analyzing Asset Price Paths Generation
The simulate_path function embodies the techniques outlined earlier. Its utility extends to the pricing of exotic options such as Binary, Asian, and Lookback options. This section conducts an analysis to observe how asset prices, when modeled using Geometric Brownian Motion (GBM), evolve over time and conform to a lognormal distribution. Additionally, we will calculate and compare the standard error of the terminal asset prices under varying parameter configurations. This comparison aims to elucidate the impact of different methodological approaches on the behavior of the process. This insight is crucial for understanding the dynamics of asset pricing in financial modeling.
def simulate_path(s0,r,T,vol,nts,n_sim,rnd='NP',approx=None,vred=None):
random.seed(2)
dt = T/nts
S = zeros((nts,n_sim))
S[0] = s0
for i in range(0, nts-1):
# Random number generators:
if rnd == 'Box-Muller':
w = Box_Muller(n_sim)
if rnd == 'NP':
w = random.standard_normal(n_sim)
if rnd == 'Halton':
w = Halton(n_sim)
# Variance reduction:
if vred=='AV':
wa = w[:int(n_sim/2)]
w = concatenate((wa,-wa), axis=0)
if vred=='MM':
w = (w - w.mean())/w.std()
if vred=='AVMM':
wa = w[:int(n_sim/2)]
w = concatenate((wa,-wa), axis=0)
w = (w - w.mean())/w.std()
# Euler-Maruyama:
if approx=='EM':
S[i+1] = S[i] * (1 + r*dt + vol*w*sqrt(dt))
# Milstein scheme:
if approx=='MS':
S[i+1] = S[i] * (1 + (r + 0.5*power(vol,2)*(power(w,2)-1))*dt + vol*w*sqrt(dt))
# Closed form solution:
if approx==None:
S[i+1] = S[i] * exp((r - 0.5*power(vol,2))*dt + vol*w*sqrt(dt))
return SThis analysis reveals distinct patterns in the distribution of asset prices based on their simulation methods:

When employing antithetic variates (AV), the asset prices exhibit a marginally narrower lognormal distribution, which remains largely unchanged upon the integration of moment matching (AV+MM). Conversely, the adoption of Halton numbers leads to a more expansive distribution. The quasi-random nature of Halton numbers results in a broader spread of simulated asset prices, accelerating the range expansion even with fewer paths. Across all methods, the mean of the asset prices aligns with the risk-free interest rate, displaying no significant method-based variation. Therefore, it’s graphically represented once as the ‘standard case’.
The standard error is computed using 
A compelling observation emerges when increasing the number of independent paths to 10,000, compared to the initial 1,000. In this scenario, the antithetic variates method no longer yields a narrower distribution. Conversely, the shape of the distribution using Halton numbers remains largely unaffected by the increase in path numbers, with the bandwidth staying relatively constant. Additionally, a higher path count significantly reduces the standard error.

Antithetic variates: While not substantially affecting the standard error, this technique narrows the range of simulated asset price paths, particularly noticeable with fewer paths.
Halton numbers: This approach leads to a more pronounced expansion of asset prices with fewer paths and potentially lower standard errors. Importantly, unlike pseudo-random realizations which widen with more paths, the shape of quasi-random realizations seems less influenced by the number of paths.
Contrasting Risk-Neutral and Real-World Valuations in Option Pricing
In the realm of option pricing, we distinguish between a risk-neutral world and the real world. In the risk-neutral setting, essential for delta-hedging, we assume the deterministic drift of a stock aligns with the risk-free interest rate, denoted as
We’ll utilize the simulate_path function to simulate several random walks, modifying the drift parameter. Initially, we set it to a risk-free interest rate (

In the left-hand diagram, where the drift is set at the 5% risk-free rate, we observe paths diverging in both upward and downward directions. All paths follow the same positive risk-neutral drift, with the apparent trend resulting purely from chance.
In the right-hand diagram, we observe the same paths, but now reflecting a real growth rate of 20%. This adjustment results in an upward shift of the paths. Nevertheless, even with an expected growth rate 
For speculative options trading, a key factor is our expectation of the real growth rate (

The call option’s value distribution under the risk-neutral measure tends to be narrower. This distribution visibly shifts rightward with an increased real drift. The final outcome, dispersed across the probability distribution, remains unpredictable, though all realizations share the same drift rate.
The cumulative probability distribution further illustrates this rightward shift when transitioning from the risk-free interest rate to the real growth rate. This shift reflects the implications of adjusting drift parameters in option pricing, emphasizing the differences between risk-neutral and real-world perspectives.
Understanding Convergence and Error Types in Monte Carlo Simulation
In Monte Carlo simulations, we typically encounter two primary sources of error:
- Convergence Error: This arises due to discretization and is linked to the size of time steps (
- Sampling Error: This error is related to the number of simulated asset paths, characterized by
. We refer to this as sampling error.
The following are some general observations and a comparison of the Euler-Maruyama and Milstein scheme to the closed form solution.

In the first diagram, we illustrate various paths generated with different numbers of time steps. For instance, one path goes from 0 to 1 in a single step, another in two steps (0 to 0.5 to 1), and so on. These paths culminate in different terminal stock prices 
In the second diagram, a single realization is shown on 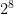
The third diagram examines the accuracy of these approximations as a function of the number of time steps. The discrepancy in terminal values 
Our preference leans towards stable algorithms that converge quickly. Fewer time steps enable more efficient option pricing.
In the forthcoming analysis, we delve into the nuances of strong and weak convergence errors, as well as the sampling error:

The diagrams we examine use the x-axis to represent the number of time steps, which increases from left to right logarithmically (base 2). Consequently, the time increment (
Strong Convergence Error: This metric is defined as the maximum of absolute error across each individual path. Generally low, this error tends to escalate for the Euler-Maruyama scheme as the number of time steps increases. In contrast, the Milstein scheme demonstrates a lower error than Euler-Maruyama, and crucially, this error does not intensify with more time steps.
Weak Convergence Error: Representing the maximum of average errors, this error is also relatively low for both the Euler-Maruyama and Milstein schemes. Weak convergence error is more pertinent to our interests, as it relates to the average error across paths, rather than individual path errors. This error is linked to the estimated payoff implications of using finite time steps.
Sampling Error: This error naturally grows with the number of time steps and is associated with the estimated payoff due to the quantity of simulated paths. In the upcoming analysis, we’ll see the sampling error depicted as a decreasing function relative to the number of simulated paths.

Interestingly, the sampling error displays notable variations only at lower numbers of simulated paths. Techniques like Halton numbers and antithetic variates initially present lower errors. However, this disparity diminishes rapidly with an increase in the number of paths.
Option Pricing
Implementing Monte Carlo Methods in Python
In our upcoming section on option pricing, we utilize three custom Python classes: Lookback_MC, Asian_MC and European_MC. These classes are designed to numerically price Lookback, Asian, and Binary/Digital options, respectively. The underlying stock simulations are conducted using the previously introduced simulate_paths function.
To distinguish between these option types, we apply Paul Wilmotts’s (2006) option classification scheme, which outlines their key characteristics:
| ASIAN | LOOKBACK | BINARY | |
|---|---|---|---|
| Time dependence | Yes, if discrete sampling No, if continuous sampling |
Yes, if discrete sampling No, if continuous sampling |
No |
| Cashflows | No | No | No |
| Path dependence | Strong | Strong | No |
| Dimensionality | 3 (possible similarity reduction) |
3 (possible similarity reduction) |
2 |
| Order | First | First | First |
| Embedded decisions | No | No | No |
Each option type shares certain attributes: they are all first-order, devoid of embedded decisions, and do not generate cashflows before expiration. Asian and Lookback options exhibit strong path dependence due to their reliance on an additional independent state variable (such as the average, maximum, or minimum stock price over time). Both of these options also show time dependence in cases where the state variable is measured at discrete intervals, like the average of the last month’s daily closing prices. In contrast, Binary options, though simpler in structure, have a discontinuous payoff, necessitating a directional stance on the underlying asset.
We will explore various versions of each option type, delve into their payoff structures, and assess the accuracy of Euler-Maruyama and Milstein methods compared to the closed-form solutions.
Binary Options
Binary options, also known as Digital options, are widely used in hedging and speculative strategies. They serve as fundamental components for constructing complex payoff structures in financial engineering (Haug 2007:174). Unlike other options, binary options inherently reflect the real drift of the underlying asset. Since delta-hedging is not feasible with binary options, taking a position in them is, to an extent, speculative (Wilmott 2006:967).
As per our earlier option classification scheme, Binary options are relatively simple. Unlike Asian and Lookback options, they lack path dependence. We will explore several binary option variants including:
- GAP Option
- Cash-or-Nothing (CON) Option
- Asset-or-Nothing (AON) Option
- Supershare Option
GAP Options
GAP options, a binary option variant, feature two strike prices: a first strike and a payoff strike. The option value can become negative if the payoff strike is higher. When both strikes are set such that the option’s initial value is zero, it is termed a pay-later option. We will analyze a GAP option with a payoff strike exceeding the primary strike:

Payoff profiles for GAP call options with varying maturities show that a higher payoff strike leads to lower cost compared to a standard call option. However, it can result in negative payoffs, as seen in the right-hand diagram. A payoff strike lower than the first strike benefits the holder if the option is in the money at expiration.
Convergence Analysis
We assess the convergence of pricing algorithms to the Black-Scholes model, comparing closed-form, Euler-Maruyama, and Milstein schemes. Variance reduction and quasi-random Halton numbers are also applied to enhance convergence:

Two diagrams demonstrate the algorithm’s convergence to the Black-Scholes price for a GAP call option. The number of simulated paths is plotted on the x-axis, and the option price on the y-axis. The dashed line represents the Black-Scholes price. One diagram uses Numpy’s pseudo-random numbers, while the other employs quasi-random Halton numbers. We have applied only 32 timesteps above. The bandwidth around expected values, denoting +/- two standard errors, narrows with more simulations. Despite both Euler-Maruyama and Milstein schemes yielding similar results, they do not fully converge to the Black-Scholes price.
The next screenshot shows improved convergence with 260 timesteps, using variance reduction techniques:

With increased timesteps, convergence improves. Halton numbers also seem to reduce perturbation.
We then compare prices for contracts with varying moneyness, simulating 5000 paths using Halton numbers. The results from closed-form, Euler-Maruyama, and Milstein methods are contrasted:

The Monte Carlo method shows minor discrepancies from the Black-Scholes price, typically within a standard error. Moneyness appears to have little effect on this outcome. However, runtimes are longer due to the combination of Halton numbers and increased timesteps.
An intriguing case arises with an at-the-money GAP option, six months to expiration:

Here, the Monte Carlo method yields a price about 14 times higher than the Black-Scholes price, using either standard Numpy random numbers or Halton numbers. This significant deviation, although small in absolute terms, is intriguing. Marsaglia’s polar method, however, gives a result closely aligned with the Black-Scholes price.
This discrepancy might be attributed to model risk. Given that Binary options, particularly GAP options, exhibit high delta at-the-money and gamma sign changes across the strike (Wilmott 2006:121 ff.), they defy delta-hedging in practice, casting doubt on the reliance on these values.
Cash-Or-Nothing Options
Cash-or-Nothing options pay a fixed amount if in the money at expiration and nothing otherwise. We examine a CON call option with a fixed payout of 

The diagrams illustrate the CON call option’s payoff profile for different maturities. In our case, the CON option has a much lower value than the plain vanilla call, since only a fixed amount of 10 is payed for the CON option that expires in the money. The payoff at expiry, shown in the diagram on the right-hand side has a typical shape of a binary option. Notably, the payoff also looks like the analytical delta of a standard call option.
Convergence Analysis
We analyze the pricing algorithms’ convergence to the Black-Scholes price, comparing closed-form, Euler-Maruyama, and Milstein schemes with variance reduction and Halton numbers:

CON option pricing proves more efficient with Monte Carlo methods. The algorithms converge swiftly to the Black-Scholes price, even with fewer timesteps. Perturbation remains minimal with reduced simulation paths. Both Euler-Maruyama and Milstein schemes offer near-identical outcomes, with Halton numbers not providing significant enhancements.
The following screenshot shows almost perfect alignment with the Black-Scholes price using Halton numbers and 260 timesteps:

In a subsequent analysis, we examine different moneyness levels, simulating 4000 paths with Halton numbers. Results from closed-form, Euler-Maruyama, and Milstein methods are compared:

Price differences from the Black-Scholes price are negligible, and the closed-form and Milstein methods deliver almost identical prices. The Euler-Maruyama scheme’s prices fall well within a standard error margin.
Asset-Or-Nothing Options
Asset-or-Nothing options pay the stock price at expiration if in the money, otherwise nothing.

AON options are pricier than standard calls as they deliver the underlying asset at expiration without requiring the strike price payment.
Convergence Analysis
We evaluate the convergence of pricing algorithms to the Black-Scholes price, comparing closed-form, Euler-Maruyama, and Milstein schemes with variance reduction and Halton numbers:

The convergence patterns of closed-form, Euler-Maruyama, and Milstein schemes to the Black-Scholes price for AON options are similar. Fewer timesteps result in slower convergence, with pseudo-random numbers being more effective in larger simulations.
The next screenshot shows smoother convergence lines using Halton numbers with 260 timesteps:

In a further analysis, we simulate options with different moneyness, creating 5000 paths using Halton numbers. We compare results from closed-form, Euler-Maruyama, and Milstein methods:

Price differences from the Black-Scholes price are smaller for at-the-money contracts. In- and out-of-the-money contracts exhibit differences exceeding two standard errors.
Supershare Options
Supershare options, with two strike levels, pay the stock price relative to the lower strike (


The Supershare option is much less expensive compared to a plain vanilla call. The reason for this is that the Supershare only pays the stock price relative to the lower strike price, if the contract expires in the money, i.e. the underlying stock price ends between the lower and the upper strike at expiration. Interestingly, the payoff for different maturities, shown in the right diagram, looks like the analytical gamma of a plain vanilla option.
Convergence Analysis
We compare the convergence of pricing algorithms to the Black-Scholes price, evaluating closed-form, Euler-Maruyama, and Milstein schemes with variance reduction and Halton numbers:

Supershares show inefficiencies with standard Monte Carlo methods, possibly due to a small proportion of paths ending in the money. Lower timesteps result in slow or no convergence.
The diagrams below use a higher number of timesteps, which leads to less perturbation – at least when we use pseudo-random numbers. Since runtimes increase very quickly with smaller timesteps, I have only tested once if the higher number of 20,000 paths leads to less perturbation, but I have not observed remarkable improvements. Probably, a variance reduction technique called importance sampling may be of help here. The following shows a screenshot from the same simulation of a Supershare but with a higher number of timesteps (NTS=512) and paths (N_SIM=10,000):

In subsequent analysis, we simulate Supershare options with varying moneyness, creating 7000 paths using Numpy random numbers. Results from closed-form, Euler-Maruyama, and Milstein methods are compared:

The price differences from the Black-Scholes model are minimal, with standard errors remaining small. Out-of-the-money contracts show differences exceeding two standard errors.
Asian Options
Asian options are strongly path dependent options as their payoff depends on an average value of the underlying asset price over some period before expiry. This characteristic distinguishes them from Binary options, where the focus is solely on the asset’s final value at expiration. In the case of Asian options, the path followed by the underlying asset throughout the option’s duration becomes crucial. Consequently, the pricing challenge for Asian options expands into a three-dimensional problem, incorporating an additional state variable that represents the average price of the asset. The use of Monte Carlo simulation in pricing these options is particularly advantageous. It simplifies the process by eliminating the need for continuous tracking of the state variable along the path. Instead, this variable is only considered during the calculation of the final payoff, making the simulation process more straightforward and efficient.
The Asian option type encompasses various types, differentiated by their observation methods and average calculations. These variations include:
- Continuous vs. Discrete Observations:
- In numerical methods, we inherently operate in discrete time, which might make the distinction between continuous and discrete observations seem somewhat abstract. However, for continuous observations in the context of Asian options, it implies that all discretely observed prices (such as daily closing prices) contribute to the average calculation of the underlying asset price for the entire option duration
.
- In contrast, discrete observations lead to a piecewise constant average. This average is periodically updated, for example, it could be calculated using all daily closing prices within a calendar month at the end of each month. Monte Carlo methods simplify this process as they only require consideration of either the most recent period or the entire lifespan of the option.
- Arithmetic vs. Geometric Average Calculation:
- While geometric average rate options have a closed-form solution for their pricing, arithmetic average rate options typically rely on analytical approximations or Monte Carlo methods for their valuation (Haug 2007:186).
I have implemented both arithmetic and geometric variants in a custom Python class, however, this analysis will focus solely on the geometric variant. Additionally, only a single comparison between the Monte Carlo results and the corresponding Black-Scholes price will be presented, rather than a comprehensive comparison as done previously. This choice is due to the focus on the discrete variant of this option type.
Given that we are dealing with path-dependent options, greater attention must be paid to setting the number of timesteps per path. Moreover, the application of quasi-random numbers like Halton sequences may not be suitable in this context. These numbers can significantly influence the trajectory of the underlying asset’s random walk, which is a crucial factor in the valuation of path-dependent options like Asian options.
Asian – Geometric Average-Rate Option
We undertake the pricing of an Asian call option while varying the time to maturity. This analysis also includes a comparison between monthly and continuous observations. For this exercise, the simulation operates on an hourly basis for each path, providing a detailed exploration of how these different factors influence the option’s pricing.

The GDAR (Geometric Discrete Average Rate) option is marginally cheaper than a standard vanilla call option. In contrast, the GCAR (Geometric Continuous Average Rate) option is noticeably less expensive than both the vanilla call and its discrete counterpart. This lower pricing for the GCAR option arises from its methodology of taking into account all asset prices up until expiration.
Convergence Analysis
With the following analysis we compare the convergence of the pricing algorithms. We compare the closed form solution with the Euler-Maruyama and the Milstein scheme . We also apply variance reduction techniques and quasi-random Halton numbers to improve convergence:

The diagrams presented above illustrate the convergence behavior using daily timesteps. The results appear satisfactory, but there is noticeable instability when the number of simulated paths is increased. Consequently, to enhance stability, we will adjust the model to operate on hourly timesteps.
The following diagrams show convergence with hourly timesteps:

In the left-hand diagram, the convergence appears stable. However, in the right-hand diagram, the application of Halton numbers seems to lead to a consistent overestimation of the Asian (GDAR) option’s value.
For our next phase of analysis, we’ll simulate the option across varying degrees of moneyness. We’ll generate 5000 paths using random numbers from the Numpy package, comparing the results from the closed-form solution, the Euler-Maruyama scheme, and the Milstein method:

We’re focusing on the geometric average rate option, considering different moneyness levels, with the simulation frequency set to hourly steps. It’s observed that the relative standard error (compared to the option price) is higher for out-of-the-money options and diminishes as the moneyness increases.
The subsequent analysis presents a comparison between the Black-Scholes and Monte Carlo prices for a geometric average rate option under continuous observation:

The Monte Carlo simulation prices align closely with those from the Black-Scholes model. This comparison reinforces the value of contrasting Monte Carlo prices derived from different random number generation techniques. Notably, the prices calculated using the Box-Muller method are more closely aligned with the Black-Scholes price, showcasing the effectiveness of this method in this context.
Lookback Options
Lookback options are typically pricier than plain vanilla options, as their valuation is based on the difference between the share price at maturity and the minimum (for a call option) or maximum (for a put option) share price observed over the option’s lifetime. For a delta long investor, this mechanism essentially represents a strategy of buying at the lowest and selling at the highest point. Similar to Asian options, Lookback options can have either continuous or discrete observations. In practical scenarios, discrete observations are more common, where the min/max values are usually updated based on specific points, such as the closing price every Friday or on the last trading day of each month. This setup implies that new highs or lows occurring outside these discrete points don’t affect the Lookback option, making it time dependent. Additionally, since the state variable is adjusted less frequently, discrete observations generally result in lower option values compared to continuous observations.
We will conduct a comparative analysis of two Lookback option variants:
- Floating Strike Lookback Call
- Fixed Strike Lookback Call
Lookback options are widely traded across various markets and asset classes, and their presence is notably growing in the fixed income sector.
Floating Strike Lookback Call
This particular type of Lookback option, as implied by its name, does not have a predetermined strike price. Instead, its payoff at expiration is determined by the difference between the final stock price (

This payoff looks very different to what we have seen before. Since we have a floating strike, which is the observed minimum over the option’s life, we end up with a linear payoff. We can see that the discrete variant has a lower value compared to the continuous pricing variant. The reason behind this is that minimum values of the underlying are less often adjusted than with continuous observations. In practical applications, continuous observations often present challenges and are typically not viable (Wilmott 2006:448).
Convergence Analysis
With the following analysis we compare the convergence of the pricing algorithms. We compare the closed form solution with the Euler-Maruyama and the Milstein scheme . We also apply variance reduction techniques and quasi-random Halton numbers to improve convergence:

The diagrams above shows a similar behavior in convergence from daily timesteps like we have observed for the Asian option. Convergence looks not too bad, but there is again some instability for simulations on a higher number of paths. We have therefore adjusted the frequency again to hourly steps.
The following diagrams show convergence with hourly timesteps:

In this scenario, the pattern observed is quite similar. On the left, we see consistent and stable convergence, whereas on the right, there appears to be a tendency to overestimate the value of the Lookback call option.
In the following we show the Monte Carlo price for a floating strike lookback call option. Therefore we generate 6000 paths and use random numbers drawn from the Numpy package. We show the prices based on the closed form solution, the Euler-Maruyama scheme and Milstein:

The analysis reveals that both the prices and standard errors are remarkably consistent across the board.
Fixed Strike Lookback Call
The payoff for a Fixed Strike Lookback Call option is calculated as the difference between the highest stock price observed during the option’s life and a pre-determined strike price. We will present examples with both continuous and monthly observations.

For a continuously observed Lookback call, the value tends to be higher than its discrete observation counterpart. Both types generally command a higher price than a plain vanilla call option. In pricing this option, we focus on the fixed strike and the maximum stock price observed over the option’s lifespan. This approach means that the timing of selling the share is not a concern.
Convergence Analysis
We proceed to evaluate the convergence of various pricing algorithms. This involves comparing the closed-form solution with the Euler-Maruyama and Milstein schemes, along with implementing variance reduction techniques and quasi-random Halton numbers for enhanced convergence:

The convergence patterns observed in the diagrams for the Fixed Strike Lookback Call option are quite similar to those seen in the floating strike variant, particularly with daily timesteps. While convergence is generally good, there is noticeable perturbation as the number of paths increases. To address this, we have shifted to hourly timestep frequency.
The subsequent diagrams showcase convergence results using hourly timesteps:

This adjustment results in consistent and stable convergence seen in the left diagram, while the right diagram indicates a tendency to overestimate the option’s value.
We then present the Monte Carlo pricing for a Fixed Strike Lookback call option. For this, we generate 6000 paths using random numbers from the Numpy package. The prices are computed based on the closed-form solution, the Euler-Maruyama scheme, and the Milstein method:

The analysis again reveals that both the prices and standard errors are remarkably consistent across the board.
Conclusion
This mini-project addresses a complex and open-ended problem. The analysis is intended to serve as a helpful starting point or a reference for practical pricing problems. Our investigation revealed that Monte Carlo methods are quite effective for obtaining preliminary results. Due to their flexibility, Monte Carlo methods can be readily adapted to various option contracts. However, the lengthy simulation times pose a constraint for empirical analysis, making it difficult to determine the most efficient and stable settings for pricing different types of options. In real-world applications, multiprocessing could potentially accelerate these simulations. Yet, not all methods are guaranteed to reduce runtimes (Hilpisch 2019:304), and so, for now, I have not implemented such features. In practice, finite difference methods are often preferred over Monte Carlo methods for their efficiency in option pricing.
I also experimented with Marsaglia’s polar method for generating random numbers in the Geometric Brownian Motion simulations but didn’t observe significant variations compared to the results using Numpy’s random number generator, which likely employs a ziggurat algorithm. Interestingly, quasi-random numbers aid in achieving faster convergence due to their more uniform distribution. However, in the analysis of Lookback and Asian options, it was noted that these numbers might lead to an overestimation bias.
Monte Carlo methods can be somewhat unwieldy. For certain option types, standard Monte Carlo methods without modifications proved inefficient, as seen in the inadequate convergence for Supershare options. Importance sampling might be a solution for better convergence in such cases. This issue of inefficiency is particularly pronounced for deep out-of-the-money options, where most simulated paths yield a zero payoff, contributing little to the pricing analysis.
It was intriguing to note that the payoff of Cash-Or-Nothing options resembles the delta of a standard vanilla call option, while Supershare options’ payoff mirrors the gamma of the same.
When comparing the closed-form solution, Euler-Maruyama, and Milstein schemes, I found no significant differences; they all led to similar outcomes. However, it’s conceivable that option prices might be more sensitive to these approximations under different circumstances. Regardless, when a closed-form solution is available, it remains the preferred choice in practical applications.
References
Boyle, P., M. Broadie and P. Glasserman, 1997: Monte Carlo Methods for Security Pricing. Journal of Economics Dynamics and Control, 21, 1257-1321.
Jäckel, Peter, 2002: Monte Carlo Methods in Finance. John Wiley & Sons, Chichester.
Haug, Espan G., 2007: The Complete Guide to Option Pricing Formulas. Second Edition. McGraw-Hill.
Hilpisch, Yves, 2019: Python for Finance. Mastering Date-Driven Finance. Second Edition. O_Reilly.
Knuth, Donald E., 1969: The Art of Computer Programming. Seminumerical Algorithms. Volume 2. Addison-Wesley.
Wilmott, Paul, 2006: Paul Wilmott on Quantitative Finance. Second Edition. John Wiley & Sons.
APPENDIX
Runtime check
The following shows the runtimes for pricing a plain vanilla european call option, based on the closed form solution, the Euler-Maruyama and the Milstein scheme. The comparison is related to different setting for the parameters #steps and #paths:

We can see that the Euler-Maruyama approximation has the shortest runtime, which is around 70%-80% compared to the closed form solution. Surprisingly, the runtime of the Milstein scheme is more than double compared to the exact solution.
In the closed form solution, the computational load imposed by the exp() function does not appear to be a major concern. However, the execution of Monte Carlo methods can become quite time-intensive, especially when dealing with very small timesteps and a large number of simulated paths. This approach is often necessary to achieve adequate levels of precision, especially for pricing options with strong path dependence, such as Asian and Lookback options.